از آنجایی که برنامه های معنایی به سرعت در حال تبدیل به موضوعات مهم در صنعت می شوند، سوالاتی غالباً در رابطه با آنتولوژی ها و گراف های معنایی پیش می آید به خصوص در رابطه با تفاوت این دو.
آیا آنتولوژی ها و گراف های دانش یکسان هستند؟ اگر نیستند تفاوتشان چیست؟ ارتباط بین این دو چیست؟
در این مطلب می خواهم به هر دو بحث بپردازم و برای شما توضیح دهم که تفاوت این دو چیست و چگونه با یکدیگر کار می کنند تا حجم زیادی از اطلاعات را سازماندهی کنند .
آنتولوژی چیست ؟
آنتولوژی ها مدلهای داده معنایی هستند که نوع اشیایی که در حوزه مورد نظر ما وجود دارند و ویژگی هایی که میتوانند برای توصیف آنها مورد استفاده قرار بگیرند را تعریف می کنند. در واقع میتوان گفت آنتولوژی ها مدلهای داده عمومی یا کلی هستند. به این معنی که آنتولوژی ها فقط به توصیف کلی یا عمومی چیزهایی که ویژگیهای معینی دارند میپردازد، اما به اطلاعات مشخص در رابطه با اعضا و موجودیتهای حاضر در آن حوزه نمی پردازد.
برای مثال به جای توصیف یک سگ و همه مشخصات آن سگ موردنظر، یک آنتولوژی باید بر روی مفاهیم عمومی سگها متمرکز شود. یعنی سعی کند ویژگی های را مطرح کند که اکثر سگ ها دارند. این کار به ما اجازه استفاده مجدد از آنتولوژی برای توصیف سایر سگ ها در آینده را می دهد.
آنتولوژی از سه بخش اصلی تشکیل شده است که به صورت زیر توصیف میشود:
- کلاس ها: یعنی انواعی از چیزها که دارای مشخصات معین و منحصربه فرد هستند که در داده های ما وجود دارد
- ارتباطات: ویژگی هایی که دو کلاس را به یکدیگر مرتبط می کنند
- خصیصهها: ویژگی هایی که کلاس یک عضو را مشخص می کنند
برای مثال در نظر بگیرید ما اطلاعات زیر را در رابطه با کتاب ها نویسندگان و منتشر کنندگان داریم :
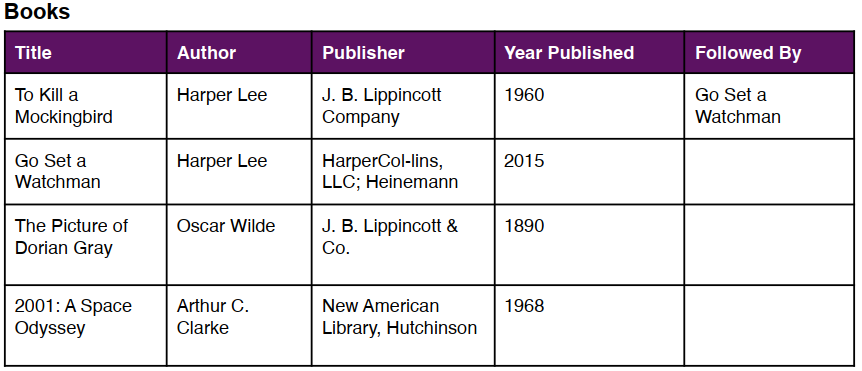
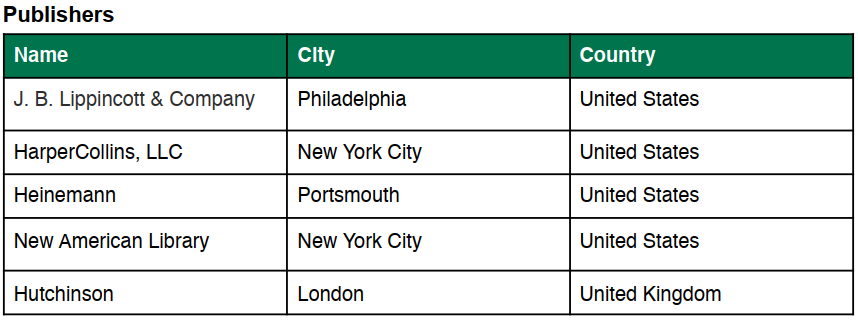

در ابتدا ما میخواهیم کلاس های مان را مشخص کنیم( یعنی انواع یکتا از چیزهایی که در دادههای ما وجود دارند)
این داده ها اطلاعات را در رابطه با کتاب ها ارائه می دهد، بنابراین کتاب گزینه مناسبی برای کلاس می باشد. به طور مشخص داده های نمونه ما، انواع مشخصی از چیزها در رابطه با کتاب در بردارند، نظیر نویسندگان و انتشارات. اگر کمی دقیق تر شویم متوجه می شویم که این داده ها همچنین اطلاعاتی را در رابطه با انتشارات و نویسندگان نیز دارد، نظیر موقعیت مکانی آنها بنابراین در نهایت با چهار کلاس زیر طرف هستیم:
- کتاب ها
- نویسندگان
- انتشارات
- موقعیت های مکانی
در مرحله بعدی لازم است که ارتباطات و مشخصه های ویژگی ها را تعیین کنیم( برای سادگی ما ارتباطات و مشخصه ها را به عنوان ویژگی در نظر می گیریم). با استفاده از کلاس هایی که ما قبلا مطرح کردیم می توانیم به داده ها نگاه کنیم و ویژگی هایی را که برای هر کلاس می بینیم لیست کنیم. برای مثال با نگاه به کلاس کتاب ویژگی هایی مانند موارد زیر مطرح میشود:
- کتابها نویسندگانی دارند
- کتابها انتشاراتی دارند
- کتاب ها در یک تاریخی منتشر میشوند
- کتاب ها توسط کتابهای دیگری مورد ارجاع قرار می گیرند
برخی از این ویژگی ها ارتباطی هستند که دو کلاس را به همدیگر متصل می کنند. برای مثال ویژگی “کتاب ها نویسندگانی دارند”، ارتباطی است که کتاب را به نویسنده متصل میکند و سایر ویژگی ها نظیر “متصل می کنند” .
لازم است که مد نظر داشته باشید که این ویژگی ها می تواند به هر کلاسی نسبت داده شود اما الزاماً قرار نیست که به هر کتابی نسبت داده شود. برای مثال خیلی از کتاب ها به سایر کتابها ارجاع نداده اند. ما هیچ مشکلی نداریم و این امری طبیعی است، چرا که ما فقط می خواهم اطمینان حاصل کنیم که ویژگی های ممکن که ممکن است به بسیاری از کتاب ها و الزاما نه همه آنها اعمال شود را در آنتولوژی مطرح کرده ایم.
همچنان که ویژگی های بالا به راحتی قابل درک و خواندن می باشد می توانیم آنها را به شیوه شهودی تری که کلاس ها و ویژگی ها از هم مجزا باشند نمایش دهیم. برای مثال “کتابها نویسندگانی دارند” می تواند به صورت زیر نوشته شود
Book → has author → Author
اگر چه خیلی ویژگی های دیگری هم هستند که میتوانید در انتولوژی لحاظ کنید که البته این موضوع به نیاز مندی های شما و مورد کاربردی شما بستگی دارد. در این آموزش صرفاً به بیان ویژگیهای زیر بسنده می کنم:
- Book → has author → Author
- Book → has publisher→ Publisher
- Book → published on → Publication date
- Book → is followed by → Book
- Author → works with → Publisher
- Publisher → located in → Location
- Location → located in → Location
به خاطر داشته باشید که آنتولوژی ما یک مدل داده کلی می باشد به این معنی که ما قصد نداریم اطلاعاتی را در رابطه با کتاب های مشخصی در آن توجه خود قرار دهیم، به جای آن میخواهیم یک چارچوب با قابلیت استفاده مجدد ایجاد کنیم که از آن بتوانیم برای توصیف سایر کتاب ها در آینده نیز استفاده کنیم وقتی ما کلاس ها و ارتباط آن را با یکدیگر ترکیب می کنیم .می توانیم آنتولوژی را به شکل یک گراف مانند تصویر زیر تصور کنیم:
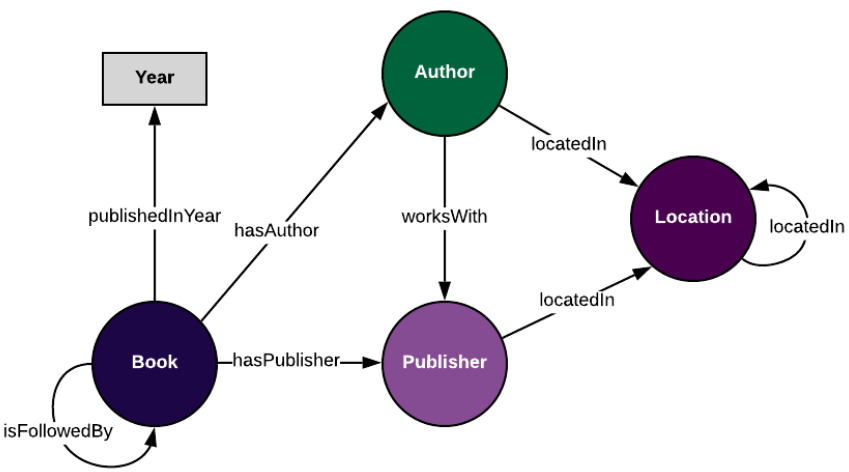
گراف دانش چیست؟
با در نظر گرفتن استفاده از آنتولوژی به عنوان یک چارچوب می توانیم داده های واقعی را در رابطه با کتاب های مشخص، نویسندگان، انتشارات و موقعیت مکانی آنها ایجاد کنیم تا یک گراف دانش را تولید کنیم.
با توجه به اطلاعاتی که در جدول بالا داشتیم همچنین با در نظر گرفتن آنتولوژی می توانیم نمونه های مشخصی از هر کدام از ارتباطات هستی شناسانه خود را ایجاد کنیم. برای مثال ما ارتباطی به صورت Book → hasauthor → Author
در آنتولوژی خود داریم یک نمونه از این ارتباط به صورت شکل زیر می باشد :
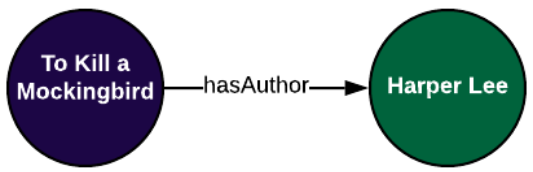
اگر ما همه اطلاعات موردی را در رابطه با یکی از کتابهای داریم ایجاد کنیم گراف دانشی مشابه تصویر زیر خواهیم داشت

اگر این کار را با تمام داده های خود انجام دهیم در نهایت با گرافی روبرو می شویم که تمام داده های آن بر مبنای آنتولوژی شکل گرفته است. با استفاده از این گراف دانش میتوانیم داده های خود را به صورت شبکه ای از ارتباطات ببینیم به جای آن که آنها را به صورت جداول جداگانه داشته باشیم. با استفاده از زبان SPARQL می توانیم از این داده ها query بگیریم و با استفاده از استنتاج، گراف دانش ما تباطاتی را برای ما ایجاد میکند که قبلاً تعریف نشده بودند.
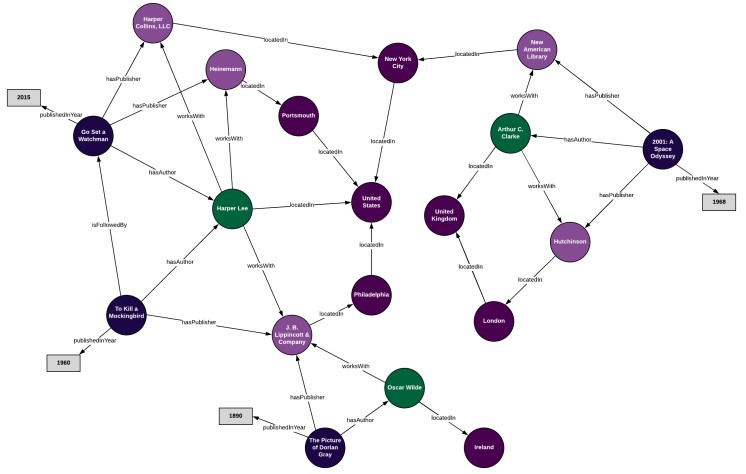
بنابراین تفاوت آنتولوژی ها با گراف دانش در چیست؟
همانطور که در مثال بالا ملاحظه کردید یک گراف دانش هنگامی ایجاد می شود که شما یک آنتولوژی ( همان دیتا مدل ما) را به یک دیتاست از داده های معین (داده های مربوط به کتاب، نویسنده و انتشارات) اعمال کنید. به بیان دیگر می توان گفت :
ontology + data = knowledge graph
در صورتی که مایل باشید می توانید پیاده سازی پروژه طراحی آنتولوژی خود را به ما بسپارید. برای اطلاعات بیشتر کلیک کنید